
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터프로그래밍
- 문법
- 코딩테스트
- MySQL
- 토이프로젝트
- 백준
- 모의해킹
- 프로그래밍
- 스프링
- 이클립스
- SQL 문법
- 스파크
- 데이터베이스
- SQL
- 위클리챌린지
- 빅데이터
- 파이썬
- 기초
- 알고리즘
- 프로그래머스
- 필기
- SQL 정리
- 문제풀이
- 자바
- 엘라스틱서치
- 해킹실습
- 오라클
- c언어
- 스프링부트
- 리눅스마스터 2급 2차
- Today
- Total
개발일기
빅데이터 Spark 사용해보기 - (1) Spark 란? 본문
빅데이터 분산처리 플랫폼
아파치 스파크를 한 마디로 정의하면 "빅데이터 처리를 위한 오픈소스 분산 처리 플랫폼" 이라고 표현할 수 있다.

또한 빅 데이터란?
"기존 데이터베이스 관리도구의 능력을 넘어서는 대량의 정형 또는 심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술"이라고 위키피디아에 정의되어 있습니다.
기존에는 정형 데이터를 RDBMS를 사용하여 큐잉, 샤딩 등의 방식으로 처리하였는데 데이터의 양이 급격하게 증가함에 따라 사진, 공영상 등을 포함하여 대용량의 다양한 데이터를 고속으로 처리해야 되는 환경에 직면하였다.
이를 효율적으로 처리하기 위해 등장한 것이 "빅데이터 분산처리 플랫폼" 이다.
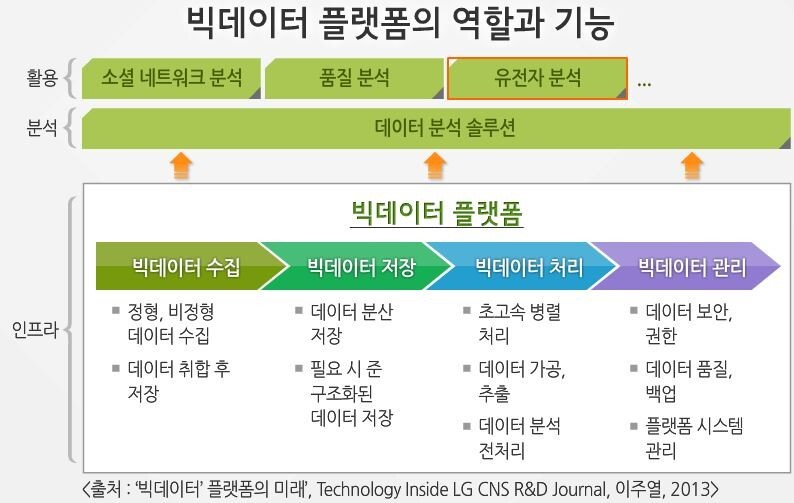
지금부터 살펴볼 아파치 스파크는 빅데이터 처리부를 편리하게 작업하기 위한 플랫폼이라고 할 수 있다.
Apache Spark의 탄생

빅데이터의 정의, 개념이 처음 등장하였을 때 빅데이터 처리는 합둡이라고 할 정도로 하둡 에코시스템이 시장을 지배했다. 하둡은 HDFS라고 불리는 분산형 파일 시스템을 기반으로 만들어졌으며, 데이터 처리시, HDFS와 "맵리듀스"라고 불리는 대형 데이터셋 병렬 처리 방식에 의해 동작한다.
문제는 하둡의 HDFS가 디스크를 기반으로 동작한다는 점, 또한 실시간성 데이터에 대한 니즈가 급격하게 증가한다는 점에서 하둡으로 처리하기에는 시간이 오래 걸려 불편하다는 일들이 생겨나기 시작했다.
이때 나타난 것이 아파치 스파크이다.
아파치는 디스크도 사용하지만 메모리를 우선적으로 사용하기 때문에 반복적인 처리를 하는 것에서 하둡보다 최소 1000배 이상 빠르다고 알려져있다. 이때문에 스파크는 데이터 실시간 스트리밍 처리라는 니즈를 충족함으로써, 빅데이터 프레임워크 시장을 빠르게 잠식해가고 있다.
'프로그래밍 이론 > Python' 카테고리의 다른 글
| Python 문법 - 문자열 뒤집기, 문자열 거꾸로 출력하기 (0) | 2021.10.12 |
|---|---|
| 빅데이터 Spark 사용해보기 - (2) Colab에서 Python 사용하기 (0) | 2021.10.05 |
| 파이썬으로 네이버 카페 데이터 크롤링하기 (2) (2) | 2021.08.27 |
| 파이썬으로 네이버 카페 데이터 크롤링 하기 (1) (2) | 2021.08.26 |
| Elasticsearch 활용한 검색엔진 만들기 (2) (0) | 2021.08.17 |



