
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- c언어
- 프로그래머스
- 스프링
- 모의해킹
- 데이터베이스
- 필기
- 문법
- SQL 정리
- 토이프로젝트
- 파이썬
- 빅데이터
- MySQL
- 데이터프로그래밍
- 기초
- SQL 문법
- SQL
- 코딩테스트
- 위클리챌린지
- 리눅스마스터 2급 2차
- 스프링부트
- 알고리즘
- 이클립스
- 자바
- 오라클
- 스파크
- 문제풀이
- 엘라스틱서치
- 해킹실습
- 백준
- 프로그래밍
- Today
- Total
개발일기
빅데이터 Spark 사용해보기 - (2) Colab에서 Python 사용하기 본문
Colab 링크 : https://colab.research.google.com/notebooks/welcome.ipynb?hl=ko
Google Colaboratory
colab.research.google.com
줄여서 Colab 이라고 하는 Colaboratory를 사용하면 브라우저에서 Python을 작성하고 실행할 수 있다.
Colab은 구성이 필요하지 않는다는 점, GPU 무료 액세스, 간편한 공유 라는 장점이 있다.
Colab은 Python 스크립트를 실행할 수 있는 코드 셀 입니다.
# Colab 사용하기
Colab을 사용하기 Python 스크립트를 실행하기 위한 GPU를 할당 받는다.

# 할당 받은 GPU의 성능 알아보기
|
1
|
!grep . /etc/*-release
|
cs |
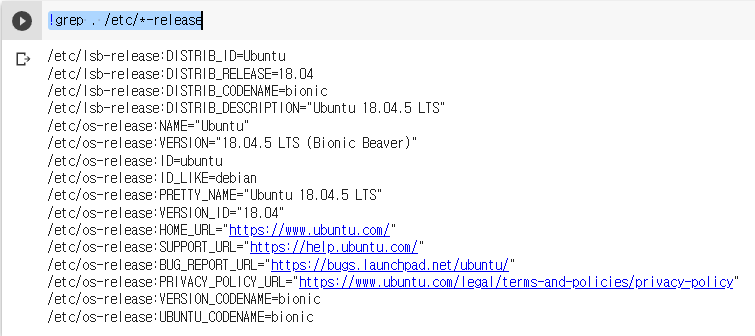
명령어를 통해 우리가 할당받은 GPU가 우분투 18.04.5 LTS 버전인 것을 확인할 수 있다.
# Colab 환경에 Spark 셋업 하기
|
1
2
3
4
5
|
!pip install pyspark
!pip install -U -q PyDrive
!apt install openjdk-8-jdk-headless -qq
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
|
cs |
스파크를 사용하기 위해 필요한 라이브러리를 설치를 진행하며 자바 또한 설치하고 환경변수 까지 설정해준다.
# Colab을 사용하기 위해 계정 인증을 진행하는 과정
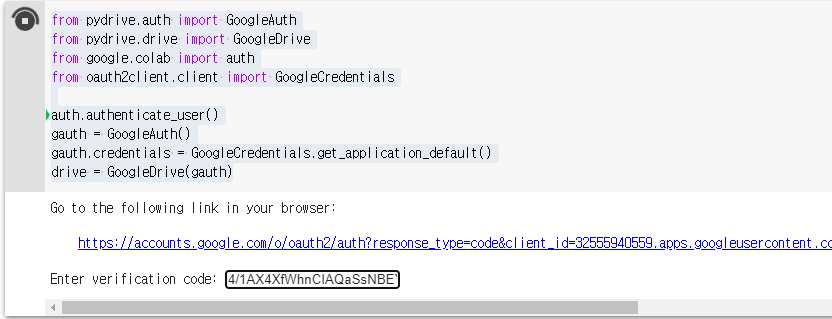
# 데이터 파일 다운로드
|
1
2
3
4
5
6
7
|
id='1L6pCQkldvdBoaEhRFzL0VnrggEFvqON4'
downloaded = drive.CreateFile({'id': id})
downloaded.GetContentFile('Bombing_Operations.json.gz')
id='14dyBmcTBA32uXPxDbqr0bFDIzGxMTWwl'
downloaded = drive.CreateFile({'id': id})
downloaded.GetContentFile('Aircraft_Glossary.json.gz')
|
cs |
데이터가 담김 파일 2개를 설치 한다.

코드를 실행하면 위처럼 정상적으로 json형태로 파일이 저장된 것을 볼 수 있다.
# Spark 사용하기
|
1
2
3
4
5
6
7
8
9
10
|
# Let's import the libraries we will need
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pyspark
from pyspark.sql import *
from pyspark.sql.functions import *
from pyspark import SparkContext, SparkConf
|
cs |
스파크를 사용하기 위해 필요한 라이브러리들을 추가한다.
|
1
2
3
4
5
6
|
# create the session
conf = SparkConf().set("spark.ui.port", "4050")
# create the context
sc = pyspark.SparkContext(conf=conf)
spark = SparkSession.builder.getOrCreate()
|
cs |
Session과 context를 생성해준다.

여기까지 완료 되었다면 spark 명령어를 입력 했을 때 정상적으로 사용 준비 되있는 것을 볼 수 있다.
# json 파일 읽기
|
1
2
|
Bombing_Operations = spark.read.json("Bombing_Operations.json.gz")
Aircraft_Glossary = spark.read.json("Aircraft_Glossary.json.gz")
|
cs |
사전에 설치한 파일들을 spark를 사용하여 읽어 데이터를 사용 준비를 한다.
# 데이터 가져오기

take(10) 명령어를 사용하여 해당 json 데이터에서 상위 10개의 데이터를 가져온다.
# 쿼리 사용하기

SQL 쿼리 문을 통해 데이터들을 요약하여 볼 수 있다. 위 데이터를 토대로 각 나라에서 몇번의 미션을 수행했는지 카운트 하여 보여준다.
여기서 SQL 쿼리문 말고 파이썬을 통해서도 표시할 수 있다.

# Pandas

MissionsCount 를 기준으로 정렬하여 보여준다.

Pandas를 사용하게 되면 위처럼 데이터의 통계를 그래프로도 표현할 수 있다.
'프로그래밍 이론 > Python' 카테고리의 다른 글
| [파이썬 자료구조] 해시 (Hash) (2) | 2021.12.01 |
|---|---|
| Python 문법 - 문자열 뒤집기, 문자열 거꾸로 출력하기 (0) | 2021.10.12 |
| 빅데이터 Spark 사용해보기 - (1) Spark 란? (2) | 2021.09.27 |
| 파이썬으로 네이버 카페 데이터 크롤링하기 (2) (2) | 2021.08.27 |
| 파이썬으로 네이버 카페 데이터 크롤링 하기 (1) (2) | 2021.08.26 |



